Pandas MultiIndex
A MultiIndex in Pandas is a hierarchical indexing structure that allows us to represent and work with higher-dimensional data efficiently.
While a typical index refers to a single column, a MultiIndex contains multiple levels of indexes. Each column in a MultiIndex is linked to one another through a parent/relationship.
Let’s take an example of a DataFrame containing the population of different countries.
import pandas as pd
# create a dictionary
data = {
"Continent": ["North America", "Europe", "Asia", "North America", "Asia", "Europe", "North America", "Asia", "Europe", "Asia"],
"Country": ["United States", "Germany", "China", "Canada", "Japan", "France", "Mexico", "India", "United Kingdom", "Nepal"],
"Population": [331002651, 83783942, 1439323776, 37742154, 126476461, 65273511, 128932753, 1380004385, 67886011, 29136808]
}
# create dataframe from dictionary
df = pd.DataFrame(data)
print(df)
Output
Continent Country Population
0 North America United States 331002651
1 Europe Germany 83783942
2 Asia China 1439323776
3 North America Canada 37742154
4 Asia Japan 126476461
5 Europe France 65273511
6 North America Mexico 128932753
7 Asia India 1380004385
8 Europe United Kingdom 67886011
9 Asia Nepal 29136808
Notice the redundancy in the Continent column. North America and Europe are repeated three times each while Asia is repeated four times.
Additionally, we have arranged the entries in a random order and used integer values as index for the rows, thus complicating the task of locating data for a particular country. This task becomes tedious as the size of the data set grows.
In situations like this, hierarchical indexing, as shown in figure below, makes much more sense.
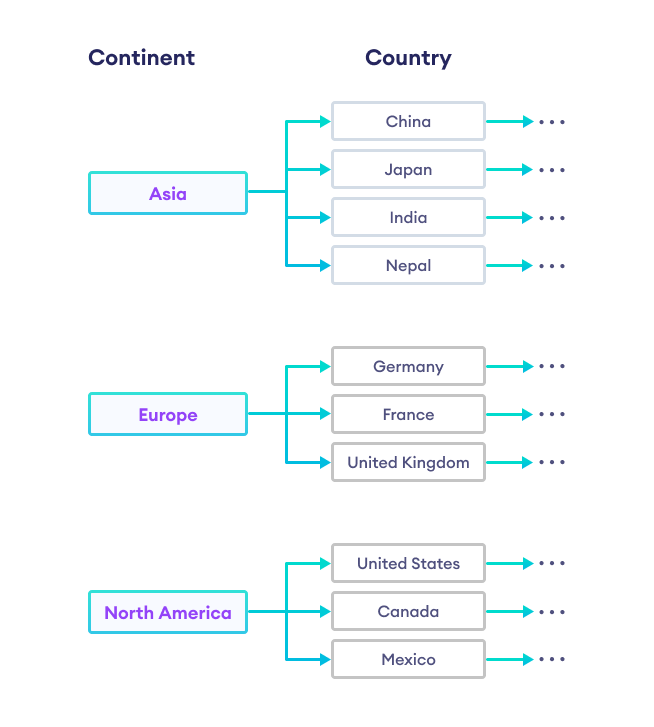 Hierarchical Index
Hierarchical Index
Here, Continent is the parent column and Country is the child column.
Create MultiIndex in Pandas
In Pandas, we achieve hierarchical indexing using the concept of MultiIndex.
Let’s see an example.
import pandas as pd
# create a dictionary
data = {
"Continent": ["North America", "Europe", "Asia", "North America", "Asia", "Europe", "North America", "Asia", "Europe", "Asia"],
"Country": ["United States", "Germany", "China", "Canada", "Japan", "France", "Mexico", "India", "United Kingdom", "Nepal"],
"Population": [331002651, 83783942, 1439323776, 37742154, 126476461, 65273511, 128932753, 1380004385, 67886011, 29136808]
}
# create dataframe from dictionary
df = pd.DataFrame(data)
# sort the data by continent
df.sort_values('Continent', inplace=True)
# create a multiindex
df.set_index(['Continent','Country'], inplace=True)
print(df)
Output
Population
Continent Country
Asia China 1439323776
Japan 126476461
India 1380004385
Nepal 29136808
Europe Germany 83783942
France 65273511
United Kingdom 67886011
North America United States 331002651
Canada 37742154
Mexico 128932753
In the above example, we first sorted the values in the dataframe df based on the Continent column. This groups the entries of the same continent together.
We then created a MultiIndex by passing a list of columns as an argument to the set_index() function.
Notice the order of the columns in the list. Continent comes first as it is the parent column and Country comes second as it is the child of Continent.
Access Rows With MultiIndex
We can access rows with MultiIndex as shown in the example below.
import pandas as pd
# create a dictionary
data = {
"Continent": ["North America", "Europe", "Asia", "North America", "Asia", "Europe", "North America", "Asia", "Europe", "Asia"],
"Country": ["United States", "Germany", "China", "Canada", "Japan", "France", "Mexico", "India", "United Kingdom", "Nepal"],
"Population": [331002651, 83783942, 1439323776, 37742154, 126476461, 65273511, 128932753, 1380004385, 67886011, 29136808]
}
# create dataframe from dictionary
df = pd.DataFrame(data)
# sort the data by continent
df.sort_values('Continent', inplace=True)
# create a multiindex
df.set_index(['Continent','Country'], inplace=True)
# access all entries under Asia
asia = df.loc['Asia']
# access Canada
canada = df.loc[('North America', 'Canada')]
print('Asia\n', asia)
print('\nCanada\n', canada)
Output
Asia
Population
Country
China 1439323776
Japan 126476461
India 1380004385
Nepal 29136808
Canada
Population 37742154
Name: (North America, Canada), dtype: int64
In the above example, we accessed all the entries under Asia by passing a single string Asia to df.loc[].
To access a particular row Canada, we passed a tuple ('North America' , 'Canada') to df.loc[].
Note: We need to provide the full hierarchical index in the form of a tuple in order to access a particular row.
Only providing the label of the child column will result in an error.
# correct
df.loc[('North America' , 'Canada')]
# error
df.loc['Canada']
MultiIndex from Arrays
We can also create a MultiIndex from an array of arrays using the from_arrays() method.
Let’s see an example.
import pandas as pd
# create arrays
continent = ['Asia', 'Asia', 'Asia', 'Asia', 'Europe', 'Europe', 'Europe', 'North America', 'North America', 'North America']
country = ['China', 'India', 'Japan', 'Nepal', 'France', 'Germany', 'United Kingdom', 'Canada', 'Mexico', 'United States']
population = [1439323776, 1380004385, 126476461, 29136808, 65273511, 83783942, 67886011, 37742154, 128932753, 331002651]
# create array of arrays
index_array = [continent, country]
# create multiindex from array
multi_index = pd.MultiIndex.from_arrays(index_array, names=['Continent', 'Country'])
# create dataframe using multiindex
df = pd.DataFrame({'Population' :population}, index=multi_index)
print(df)
Output
Population
Continent Country
Asia China 1439323776
India 1380004385
Japan 126476461
Nepal 29136808
Europe France 65273511
Germany 83783942
United Kingdom 67886011
North America Canada 37742154
Mexico 128932753
United States 331002651
In this example, we created a MultiIndex object named multi_index from two arrays: continent and country.
We then created a DataFrame using the population array and assigned multi_index as its index.