Pandas Pivot
The pivot() function in Pandas reshapes data based on column values. It takes simple column-wise data as input, and groups the entries into a two-dimensional table.
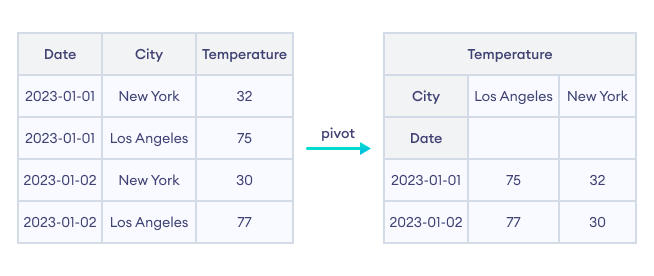 Pivot Operation in Pandas
Pivot Operation in Pandas
Let’s look at an example.
import pandas as pd
# create a dataframe
data = {'Date': ['2023-01-01', '2023-01-01', '2023-01-02', '2023-01-02'],
'City': ['New York', 'Los Angeles', 'New York', 'Los Angeles'],
'Temperature': [32, 75, 30, 77]}
df = pd.DataFrame(data)
print("Original DataFrame\n", df)
print()
# pivot the dataframe
pivot_df = df.pivot(index='Date', columns='City', values='Temperature')
print("Reshaped DataFrame\n", pivot_df)
Output
Original DataFrame
Date City Temperature
0 2023-01-01 New York 32
1 2023-01-01 Los Angeles 75
2 2023-01-02 New York 30
3 2023-01-02 Los Angeles 77
Reshaped DataFrame
City Los Angeles New York
Date
2023-01-01 75 32
2023-01-02 77 30
In this example, we used pivot() to reshape the DataFrame df. The Date column is set as index, City as columns and Temperature as values.
Notice the original and reshaped DataFrame in the output section. The reshaped DataFrame is a multidimensional table that shows the temperature based on the city and the date.
Thus the pivot() operation reshapes the data to make it clearer for further analysis.
pivot() syntax
The syntax of pivot() in Pandas is:
df.pivot(index=None, columns=None, values=None)
Here,
index: the column to use as row labelscolumns: the column that will be reshaped as columnsvalues: the column(s) to use for the new DataFrame’s values
Example: pivot() for Multiple Values
If we omit the values argument in pivot(), it selects all the remaining columns (besides the ones specified index and columns) as values for the pivot table.
Let’s see an example.
import pandas as pd
# create a dataframe
data = {'Date': ['2023-01-01', '2023-01-01', '2023-01-02', '2023-01-02'],
'City': ['New York', 'Los Angeles', 'New York', 'Los Angeles'],
'Temperature': [32, 75, 30, 77],
'Humidity': [80, 10, 85, 5]}
df = pd.DataFrame(data)
print('Original DataFrame')
print(df)
print()
# pivot the dataframe
pivot_df = df.pivot(index='Date', columns='City')
print('Reshaped DataFrame')
print(pivot_df)
Output
Original DataFrame
Date City Temperature Humidity
0 2023-01-01 New York 32 80
1 2023-01-01 Los Angeles 75 10
2 2023-01-02 New York 30 85
3 2023-01-02 Los Angeles 77 5
Reshaped DataFrame
Temperature Humidity
City Los Angeles New York Los Angeles New York
Date
2023-01-01 75 32 10 80
2023-01-02 77 30 5 85
In this example, we created a pivot table for multiple values i.e. Temperature and Humidity.
pivot() vs pivot_table()
The pivot() and pivot_table() functions perform similar operations but with few key differences.
| Basis | pivot() | pivot_table() |
|---|---|---|
| Aggregation | Does not allow aggregation of data. | Allows aggregation (sum, mean, count, etc.). |
| Duplicate Index | Cannot handle duplicate index values. | Can handle duplicate index values. |
| MultiIndex | Only accepts a single-level index. | Accepts multi-level index for complex data. |